
Here you will find the personal blogs of Samba developers (for those that keep them). More information about members can also be found on the Samba Team page.
Planet Samba
May 14, 2021
Jelmer
Ognibuild
The Debian Janitor is an automated system that commits fixes for (minor) issues in Debian packages that can be fixed by software. It gradually started proposing merges in early December. The first set of changes sent out ran lintian-brush on sid packages maintained in Git. This post is part of a series about the progress of the Janitor.
The FOSS world uses a wide variety of different build tools; given a git repository or tarball, it can be hard to figure out how to build and install a piece of software.
Humans will generally know what build tool a project is using when they check out a project from git, or they can read the README. And even then, the answer may not always be straightforward to everybody. For automation, there is no obvious place to figure out how to build or install a project.
Debian
For Debian packages, Debian maintainers generally will have determined that the appropriate tools to invoke are, and added appropriate invocations to debian/rules. This is really nice when rebuilding all of Debian - one can just invoke debian/rules - a consistent interface - and it will in turn invoke the right tools to build the package, meeting a long list of requirements.
With newer versions of debhelper and most common build systems, debhelper can figure a lot of this out automatically - the maintainer just has to add the appropriate build and run time dependencies.
However, debhelper needs to be consistent in its behaviour per compat level - otherwise builds might start failing with different versions of debhelper, when the autodetection logic is changed. debhelper can also only do the right thing if all the necessary dependencies are present. debhelper also only functions in the context of a Debian package.
Ognibuild
Ognibuild is a new tool that figures out the build system in use by an upstream project, as well as the other dependencies it needs. This information can then be used to invoke said build system, or to e.g. add missing build dependencies to a Debian package.
Ognibuild uses a variety of techniques to work out what the dependencies for an upstream package are:
- Extracting dependencies and other requirements declared in build system metadata (e.g. setup.py)
- Attempting builds and parsing build logs for missing dependencies (repeating until the build succeeds), calling out to buildlog-consultant
Once it is determined which dependencies are missing, they can be resolved in a variety of ways. Apt can be invoked to install missing dependencies on Debian systems (optionally in a chroot) or ecosystem-specific tools can be used to do so (e.g. pypi or cpan). Instead of installing packages, the tool can also simply inform the user about the missing packages and commands to install them, or update a Debian package appropriately (this is what deb-fix-build does).
The target audience of ognibuild are people who need to (possibly from automation) build a variety of projects from different ecosystems or users who are looking to just install a project from source. Developers who are just hacking on e.g. a Python project are better off directly invoking the ecosystem-native tools rather than a wrapper like ognibuild.
Supported ecosystems
(Partially) supported ecosystems currently include:
- Combinations of make and autoconf, automake or CMake
- Python, including fetching packages from pypi
- Perl, including fetching packages from cpan
- Haskell, including fetching from hackage
- Ninja/Meson
- Maven
- Rust, including fetching packages from crates.io
- PHP Pear
- R, including fetching packages from CRAN and Bioconductor
For a full list, see the README.
Usage
Ognibuild provides a couple of top-level subcommands that will seem familiar to anybody who has used a couple of other build systems:
- ogni clean - remove build artifacts
- ogni dist - create a dist tarball
- ogni build - build the project in the current directory
- ogni test - run the test suite
- ogni install - install the project somewhere
- ogni info - display project information including discovered build system and dependencies
- ogni exec - run an arbitrary command but attempt to resolve issues like missing dependencies
These tools all take a couple of common options:
—resolve=apt|auto|native
Specifies how to resolve any missing dependencies:
- apt: install the appropriate dependency using apt
- native: install dependencies using native tools like pip or cpan
- auto: invoke either apt or native package install, depending on whether the current user is allowed to invoke apt
—schroot=name
Run inside of a schroot.
—explain
do not make any changes but tell the user which native on apt packages they could install.
There are also subcommand-specific options, e.g. to install to a specific directory on restrict which tests are run.
Examples
Creating a dist tarball
1 2 3 4 5 6 7 8 9 | % git clone https://github.com/dulwich/dulwich
% cd dulwich
% ogni --schroot=unstable-amd64-sbuild dist
…
Writing dulwich-0.20.21/setup.cfg
creating dist
Creating tar archive
removing 'dulwich-0.20.21' (and everything under it)
Found new tarball dulwich-0.20.21.tar.gz in /var/run/schroot/mount/unstable-amd64-sbuild-974d32d7-6f10-4e77-8622-b6a091857e85/build/tmpucazj7j7/package/dist.
|
Installing ldb from source, resolving dependencies using apt
1 2 3 4 5 6 7 8 9 | % wget https://download.samba.org/pub/ldb/ldb-2.3.0.tar.gz
% tar xvfz ldb-2.3.0.tar.gz
% cd ldb-2.3.0
% ogni install --prefix=/tmp/ldb
…
+ install /tmp/ldb/include/ldb.h (from include/ldb.h)
…
Waf: Leaving directory `/tmp/ldb-2.3.0/bin/default'
'install' finished successfully (11.395s)
|
Running all tests from XML::LibXML::LazyBuilder
1 2 3 4 5 6 | % wget ``https://cpan.metacpan.org/authors/id/T/TO/TORU/XML-LibXML-LazyBuilder-0.08.tar.gz`_ <https://cpan.metacpan.org/authors/id/T/TO/TORU/XML-LibXML-LazyBuilder-0.08.tar.gz>`_
% tar xvfz XML-LibXML-LazyBuilder-0.08.tar.gz
Cd XML-LibXML-LazyBuilder-0.08
% ogni test
…
|
Current Status
ognibuild is still in its early stages, but works well enough that it can detect and invoke the build system for most of the upstream projects packaged in Debian. If there are buildsystems that it currently lacks support for or other issues, then I’d welcome any bug reports.
April 11, 2021
Jelmer
The upstream ontologist
The Debian Janitor is an automated system that commits fixes for (minor) issues in Debian packages that can be fixed by software. It gradually started proposing merges in early December. The first set of changes sent out ran lintian-brush on sid packages maintained in Git. This post is part of a series about the progress of the Janitor.
The upstream ontologist is a project that extracts metadata about upstream projects in a consistent format. It does this with a combination of heuristics and reading ecosystem-specific metadata files, such as Python’s setup.py, rust’s Cargo.toml as well as e.g. scanning README files.
Supported Data Sources
It will extract information from a wide variety of sources, including:
- Python package metadata (PKG-INFO, setup.py, setup.cfg, pyproject.toml)
- package.json
- composer.json
- package.xml
- Perl package metadata (dist.ini, META.json, META.yml, Makefile.PL)
- Perl POD files
- GNU configure files
- R DESCRIPTION files
- Rust Cargo.toml
- maven pom.xml
- metainfo.xml
- .git/config
- SECURITY.md
- DOAP
- Haskell cabal files
- Ruby gemspec files
- go.mod
- README{,.rst,.md} files
- Debian packaging metadata (debian/watch, debian/control, debian/rules, debian/get-orig-source.sh, debian/copyright, debian/patches)
Supported Fields
Fields that it currently provides include:
- Homepage: homepage URL
- Name: name of the upstream project
- Contact: contact address of some sort of the upstream (e-mail, mailing list URL)
- Repository: VCS URL
- Repository-Browse: Web URL for viewing the VCS
- Bug-Database: Bug database URL (for web viewing, generally)
- Bug-Submit: URL to use to submit new bugs (either on the web or an e-mail address)
- Screenshots: List of URLs with screenshots
- Archive: Archive used - e.g. SourceForge
- Security-Contact: e-mail or URL with instructions for reporting security issues
- Documentation: Link to documentation on the web:
- Wiki: Wiki URL
- Summary: one-line description of the project
- Description: longer description of the project
- License: Single line license description (e.g. “GPL 2.0”) as declared in the metadata[1]
- Copyright: List of copyright holders
- Version: Current upstream version
- Security-MD: URL to markdown file with security policy
All data fields have a “certainty” associated with them (“certain”, “confident”, “likely” or “possible”), which gets set depending on how the data was derived or where it was found. If multiple possible values were found for a specific field, then the value with the highest certainty is taken.
Interface
The ontologist provides a high-level Python API as well as two command-line tools that can write output in two different formats:
- guess-upstream-metadata writes DEP-12-like YAML output
- autodoap writes DOAP files
For example, running guess-upstream-metadata on dulwich:
% guess-upstream-metadata
<string>:2: (INFO/1) Duplicate implicit target name: "contributing".
Name: dulwich
Repository: https://www.dulwich.io/code/
X-Security-MD: https://github.com/dulwich/dulwich/tree/HEAD/SECURITY.md
X-Version: 0.20.21
Bug-Database: https://github.com/dulwich/dulwich/issues
X-Summary: Python Git Library
X-Description: |
This is the Dulwich project.
It aims to provide an interface to git repos (both local and remote) that
doesn't call out to git directly but instead uses pure Python.
X-License: Apache License, version 2 or GNU General Public License, version 2 or later.
Bug-Submit: https://github.com/dulwich/dulwich/issues/new
Lintian-Brush
lintian-brush can update DEP-12-style debian/upstream/metadata files that hold information about the upstream project that is packaged as well as the Homepage in the debian/control file based on information provided by the upstream ontologist. By default, it only imports data with the highest certainty - you can override this by specifying the —uncertain command-line flag.
| [1] | Obviously this won’t be able to describe the full licensing situation for many projects. Projects like scancode-toolkit are more appropriate for that. |
April 06, 2021
Jelmer
Automatic Fixing of Debian Build Dependencies
The Debian Janitor is an automated system that commits fixes for (minor) issues in Debian packages that can be fixed by software. It gradually started proposing merges in early December. The first set of changes sent out ran lintian-brush on sid packages maintained in Git. This post is part of a series about the progress of the Janitor.
In my last blogpost, I introduced the buildlog consultant - a tool that can identify many reasons why a Debian build failed.
For example, here’s a fragment of a build log where the Build-Depends lack python3-setuptools:
849 850 851 852 853 854 855 856 857 858 | dpkg-buildpackage: info: host architecture amd64
fakeroot debian/rules clean
dh clean --with python3,sphinxdoc --buildsystem=pybuild
dh_auto_clean -O--buildsystem=pybuild
I: pybuild base:232: python3.9 setup.py clean
Traceback (most recent call last):
File "/<<PKGBUILDDIR>>/setup.py", line 2, in <module>
from setuptools import setup
ModuleNotFoundError: No module named 'setuptools'
E: pybuild pybuild:353: clean: plugin distutils failed with: exit code=1: python3.9 setup.py clean
|
The buildlog consultant can identify the line in bold as being key, and interprets it:
% analyse-sbuild-log --json ~/build.log
{
"stage": "build",
"section": "Build",
"lineno": 857,
"kind": "missing-python-module",
"details": {"module": "setuptools", "python_version": 3, "minimum_version": null}
}
Automatically acting on buildlog problems
A common reason why Debian builds fail is missing dependencies or incorrect versions of dependencies declared in the package build depends.
Based on the output of the buildlog consultant, it is possible in many cases to determine what dependency needs to be added to Build-Depends. In the example given above, we can use apt-file to look for the package that contains the path /usr/lib/python3/dist-packages/setuptools/__init__.py - and voila, we find python3-setuptools:
% apt-file search /usr/lib/python3/dist-packages/setuptools/__init__.py
python3-setuptools: /usr/lib/python3/dist-packages/setuptools/__init__.py
The deb-fix-build command automates these steps:
- It builds the package using sbuild; if the package successfully builds then it just exits successfully
- It tries to identify the problem by looking through the build log; if it can’t or if it’s a problem it has seen before (but apparently failed to resolve), then it exits with a non-zero exit code
- It tries to find a dependency that can address the problem
- It updates Build-Depends in debian/control or Depends in debian/tests/control
- Go to step 1
This takes away the tedious manual process of building a package, discovering that a dependency is missing, updating Build-Depends and trying again.
For example, when I ran deb-fix-build while packaging saneyaml, the output looks something like this:
% deb-fix-build
Using output directory /tmp/tmpyz0nkgqq
Using sbuild chroot unstable-amd64-sbuild
Using fixers: …
Building debian packages, running 'sbuild --no-clean-source -A -s -v'.
Attempting to use fixer upstream requirement fixer(apt) to address MissingPythonDistribution('setuptools_scm', python_version=3, minimum_version='4')
Using apt-file to search apt contents
Adding build dependency: python3-setuptools-scm (>= 4)
Building debian packages, running 'sbuild --no-clean-source -A -s -v'.
Attempting to use fixer upstream requirement fixer(apt) to address MissingPythonDistribution('toml', python_version=3, minimum_version=None)
Adding build dependency: python3-toml
Building debian packages, running 'sbuild --no-clean-source -A -s -v'.
Built 0.5.2-1- changes files at [‘saneyaml_0.5.2-1_amd64.changes’].
And in our Git repository, we see these changes as well:
% git log -p
commit 5a1715f4c7273b042818fc75702f2284034c7277 (HEAD -> master)
Author: Jelmer Vernooij <jelmer@jelmer.uk>
Date: Sun Apr 4 02:35:56 2021 +0100
Add missing build dependency on python3-toml.
diff --git a/debian/control b/debian/control
index 5b854dc..3b27b73 100644
--- a/debian/control
+++ b/debian/control
@@ -1,6 +1,6 @@
Rules-Requires-Root: no
Standards-Version: 4.5.1
-Build-Depends: debhelper-compat (= 12), dh-sequence-python3, python3-all, python3-setuptools (>= 50), python3-wheel, python3-setuptools-scm (>= 4)
+Build-Depends: debhelper-compat (= 12), dh-sequence-python3, python3-all, python3-setuptools (>= 50), python3-wheel, python3-setuptools-scm (>= 4), python3-toml
Testsuite: autopkgtest-pkg-python
Source: python-saneyaml
Priority: optional
commit f03047da80fcd8468ee231fbc4cf8488d7a0acd1
Author: Jelmer Vernooij <jelmer@jelmer.uk>
Date: Sun Apr 4 02:35:34 2021 +0100
Add missing build dependency on python3-setuptools-scm (>= 4).
diff --git a/debian/control b/debian/control
index a476cc2..5b854dc 100644
--- a/debian/control
+++ b/debian/control
@@ -1,6 +1,6 @@
Rules-Requires-Root: no
Standards-Version: 4.5.1
-Build-Depends: debhelper-compat (= 12), dh-sequence-python3, python3-all, python3-setuptools (>= 50), python3-wheel
+Build-Depends: debhelper-compat (= 12), dh-sequence-python3, python3-all, python3-setuptools (>= 50), python3-wheel, python3-setuptools-scm (>= 4)
Testsuite: autopkgtest-pkg-python
Source: python-saneyaml
Priority: optional
Using deb-fix-build
You can run deb-fix-build by installing the ognibuild package from unstable. The only requirements for using it are that:
- The package is maintained in Git
- A sbuild schroot is available for use
Caveats
deb-fix-build is fairly easy to understand, and if it doesn’t work then you’re no worse off than you were without it - you’ll have to add your own Build-Depends.
That said, there are a couple of things to keep in mind:
- At the moment, it doesn’t distinguish between general, Arch or Indep Build-Depends.
- It can only add dependencies for things that are actually in the archive
- Sometimes there are multiple packages that can provide a file, command or python package - it tries to find the right one with heuristics but doesn’t always get it right
April 05, 2021
Jelmer
The Buildlog Consultant
The Debian Janitor is an automated system that commits fixes for (minor) issues in Debian packages that can be fixed by software. It gradually started proposing merges in early December. The first set of changes sent out ran lintian-brush on sid packages maintained in Git. This post is part of a series about the progress of the Janitor.
Reading build logs
Build logs for Debian packages can be quite long and difficult for a human to read. Anybody who has looked at these logs trying to figure out why a build failed will have spent time scrolling through them and skimming for certain phrases (lines starting with “error:” for example). In many cases, you can spot the problem in the last 10 or 20 lines of output – but it’s also quite common that the error is somewhere at the beginning of many pages of error output.
The buildlog consultant
The buildlog consultant project attempts to aid in this process by parsing sbuild and non-Debian (e.g. the output of “make”) build logs and trying to identify the key line that explains why a build failed. It can then either display this specific line, or a fragment of the log around surrounding the key line.
Classification
In addition to finding the key line explaining the failure, it can also classify and parse the error in many cases and return a result code and some metadata.
For example, in a failed build of gnss-sdr that has produced 2119 lines of output, the reason for the failure is that log4cpp is missing – which is on line 641:
634 635 636 637 638 639 640 641 642 643 644 645 646 647 | -- Required GNU Radio Component: ANALOG missing!
-- Could NOT find GNURADIO (missing: GNURADIO_RUNTIME_FOUND)
-- Could NOT find PkgConfig (missing: PKG_CONFIG_EXECUTABLE)
-- Could NOT find LOG4CPP (missing: LOG4CPP_INCLUDE_DIRS
LOG4CPP_LIBRARIES)
CMake Error at CMakeLists.txt:593 (message):
*** Log4cpp is required to build gnss-sdr
-- Configuring incomplete, errors occurred!
See also "/<<PKGBUILDDIR>>/obj-x86_64-linux-gnu/CMakeFiles/
CMakeOutput.log".
See also "/<<PKGBUILDDIR>>/obj-x86_64-linux-gnu/CMakeFiles/
CMakeError.log".
|
In this case, the buildlog consultant can both figure out line was problematic and what the problem was:
% analyse-sbuild-log build.log
Failed stage: build
Section: build
Failed line: 641:
*** Log4cpp is required to build gnss-sdr
Error: Missing dependency: Log4cpp
Or, if you’d like to do something else with the output, use JSON output:
% analyse-sbuild-log --json build.log
{"stage": "build", "section": "Build", "lineno": 641, "kind": "missing-dependency", "details": {"name": "Log4cpp""}}
How it works
The consultant does some structured parsing (most notably it can parse the sections from a sbuild log), but otherwise is a large set of carefully crafted regular expressions and heuristics. It doesn’t always find the problem, but has proven to be fairly accurate. It is constantly improved as part of the Debian Janitor project, and that exposes it to a wide variety of different errors.
You can see the classification and error detection in action on the result codes page of the Janitor.
Using the buildlog consultant
You can get the buildlog consultant from either pip or Debian unstable (package: python3-buildlog-consultant ).
The buildlog consultant comes with two scripts – analyse-build-log and analyse-sbuild-log, for analysing build logs and sbuild logs respectively.
February 26, 2021
Rusty
A Model for Bitcoin Soft Fork Activation
TL;DR: There should be an option, taproot=lockintrue, which allows users to set lockin-on-timeout to true. It should not be the default, though.
As stated in my previous post, we need actual consensus, not simply the appearance of consensus. I’m pretty sure we have that for taproot, but I would like a template we can use in future without endless debate each time.
- Giving every group a chance to openly signal for (or against!) gives us the most robust assurance that we actually have consensus. Being able to signal opposition is vital, since everyone can lie anyway; making opposition difficult just reduces the reliability of the signal.
- Developers should not activate. They’ve tried to assure themselves that there’s broad approval of the change, but that’s not really a transferable proof. We should be concerned about about future corruption, insanity, or groupthink. Moreover, even the perception that developers can set the rules will lead to attempts to influence them as Bitcoin becomes more important. As a (non-Bitcoin-core) developer I can’t think of a worse hell myself, nor do we want to attract developers who want to be influenced!
- Miner activation is actually brilliant. It’s easy for everyone to count, and majority miner enforcement is sufficient to rely on the new rules. But its real genius is that miners are most directly vulnerable to the economic majority of users: in a fork they have to pick sides continuously knowing that if they are wrong, they will immediately suffer economically through missed opportunity cost.
- Of course, economic users are ultimately in control. Any system which doesn’t explicitly encode that is fragile; nobody would argue that fair elections are unnecessary because if people were really dissatisfied they could always overthrow the government themselves! We should make it as easy for them to exercise this power as possible: this means not requiring them to run unvetted or home-brew modifications which will place them at more risk, so developers need to supply this option (setting it should also change the default User-Agent string, for signalling purposes). It shouldn’t be an upgrade either (which inevitably comes with other changes). Such a default-off option provides both a simple method, and a Schelling point for the lockinontimeout parameters. It also means much less chance of this power being required: “Si vis pacem, para bellum“.
This triumverate model may seem familiar, being widely used in various different governance systems. It seems the most robust to me, and is very close to what we have evolved into already. Formalizing it reduces uncertainty for any future changes, as well.
February 18, 2021
Rusty
Bitcoin Consensus and Solidarity
Bitcoin’s consensus rules define what is valid, but this isn’t helpful when we’re looking at changing the rules themselves. The trend in Bitcoin has been to make such changes in an increasingly inclusive and conservative manner, but we are still feeling our way through this, and appreciating more nuance each time we do so.
To use Bitcoin, you need to remain in the supermajority of consensus on what the rules are. But you can never truly know if you are. Everyone can signal, but everyone can lie. You can’t know what software other nodes or miners are running: even expensive testing of miners by creating an invalid block only tests one possible difference, may still give a false negative, and doesn’t mean they can’t change a moment later.
This risk of being left out is heightened greatly when the rules change. This is why we need to rely on multiple mechanisms to reassure ourselves that consensus will be maintained:
- Developers assure themselves that the change is technically valid, positive and has broad support. The main tools for this are open communication, and time. Developers signal support by implementing the change.
- Users signal their support by upgrading their nodes.
- Miners signal their support by actually tagging their blocks.
We need actual consensus, not simply the appearance of consensus. Thus it is vital that all groups know they can express their approval or rejection, in a way they know will be heard by others. In the end, the economic supermajority of Bitcoin users can set the rules, but no other group or subgroup should have inordinate influence, nor should they appear to have such control.
The Goodwill Dividend
A Bitcoin community which has consensus and knows it is not only safest from a technical perspective: the goodwill and confidence gives us all assurance that we can make (or resist!) changes in future.
It will also help us defend against the inevitable attacks and challenges we are going to face, which may be a more important effect than any particular soft-fork feature.
February 03, 2021
Andreas
socket_wrapper 1.3.0 and fd-passing
A new version of socket_wrapper has just been released.
In short, socket_wrapper is a library passing all socket communications through unix sockets. It aims to help client/server software development teams willing to gain full functional test coverage. It makes possible to run several instances of the full software stack on the same machine and perform locally functional testing of complex network configurations.
New in version 1.3.0 is support for fd-passing. This allows to send or receive a set of open file descriptors from another process. As socket_wrapper redirects all communications, happening via IPv4/IPv6 sockets and emulate those using traditional unix domain sockets, when we pass a file descriptor we also need to pass additional information with socket_wrapper. This information includes IP data and data for pcap support.
Why did we implement this?
In the meantime Samba has support for SMB3 multichannel. Multichannel support has been implemented using fd-passing in Samba and to be able to test this as part of the Samba testsuite, we need to have support for it in socket_wrapper.
CHANGELOG
- Added support for fd-passing via unix sockets
- Added (de)contructor support on AIX with pragma init/finish
- Fixed mutex fork handling
October 24, 2020
Jelmer
Debian Janitor: Hosters used by Debian packages
The Debian Janitor is an automated system that commits fixes for (minor) issues in Debian packages that can be fixed by software. It gradually started proposing merges in early December. The first set of changes sent out ran lintian-brush on sid packages maintained in Git. This post is part of a series about the progress of the Janitor.
The Janitor knows how to talk to different hosting platforms. For each hosting platform, it needs to support the platform- specific API for creating and managing merge proposals. For each hoster it also needs to have credentials.
At the moment, it supports the GitHub API, Launchpad API and GitLab API. Both GitHub and Launchpad have only a single instance; the GitLab instances it supports are gitlab.com and salsa.debian.org.
This provides coverage for the vast majority of Debian packages that can be accessed using Git. More than 75% of all packages are available on salsa - although in some cases, the Vcs-Git header has not yet been updated.
Of the other 25%, the majority either does not declare where it is hosted using a Vcs-* header (10.5%), or have not yet migrated from alioth to another hosting platform (9.7%). A further 2.3% are hosted somewhere on GitHub (2%), Launchpad (0.18%) or GitLab.com (0.15%), in many cases in the same repository as the upstream code.
The remaining 1.6% are hosted on many other hosts, primarily people’s personal servers (which usually don’t have an API for creating pull requests).

Outdated Vcs-* headers
It is possible that the 20% of packages that do not have a Vcs-* header or have a Vcs header that say there on alioth are actually hosted elsewhere. However, it is hard to know where they are until a version with an updated Vcs-Git header is uploaded.
The Janitor primarily relies on vcswatch to find the correct locations of repositories. vcswatch looks at Vcs-* headers but has its own heuristics as well. For about 2,000 packages (6%) that still have Vcs-* headers that point to alioth, vcswatch successfully finds their new home on salsa.
Merge Proposals by Hoster
These proportions are also visible in the number of pull requests created by the Janitor on various hosters. The vast majority so far has been created on Salsa.
| Hoster | Open | Merged & Applied | Closed |
| github.com | 92 | 168 | 5 |
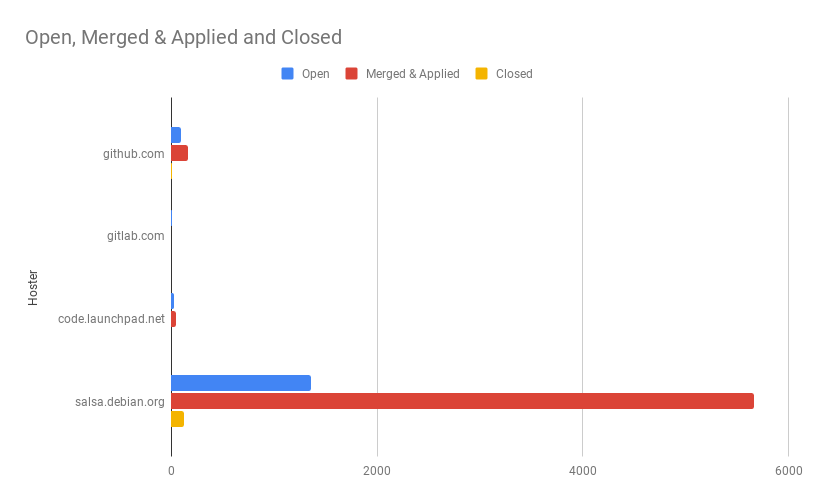
In this graph, “Open” means that the pull request has been created but likely nobody has looked at it yet. Merged means that the pull request has been marked as merged on the hoster, and applied means that the changes have ended up in the packaging branch but via a different route (e.g. cherry-picked or manually applied). Closed means that the pull request was closed without the changes being incorporated.
Note that this excludes ~5,600 direct pushes, all of which were to salsa-hosted repositories.
See also:
- Historical graphs on trends.debian.net with number of packages per VCS and per hoster (purely based on Vcs-* headers in the archive, with no heuristics applied)
- Zack’s table of number of Vcs-* header by system (Git, Svn, etc)
- current Janitor merge proposal statistics
For more information about the Janitor’s lintian-fixes efforts, see the landing page.
October 15, 2020
Jelmer
Debian Janitor: How to Contribute Lintian-Brush Fixers
The Debian Janitor is an automated system that commits fixes for (minor) issues in Debian packages that can be fixed by software. It gradually started proposing merges in early December. The first set of changes sent out ran lintian-brush on sid packages maintained in Git. This post is part of a series about the progress of the Janitor.
lintian-brush can currently fix about 150 different issues that lintian can report, but that’s still a small fraction of the more than thousand different types of issue that lintian can detect.
If you’re interested in contributing a fixer script to lintian-brush, there is now a guide that describes all steps of the process:
- how to identify lintian tags that are good candidates for automated fixing
- creating test cases
- writing the actual fixer
For more information about the Janitor’s lintian-fixes efforts, see the landing page.
September 30, 2020
David
QEMU/KVM Bridged Network with TAP interfaces
In my previous post, Rapid Linux Kernel Dev/Test with QEMU, KVM and Dracut, I described how build and boot a Linux kernel quickly, making use of port forwarding between hypervisor and guest VM for virtual network traffic.
This post describes how to plumb the Linux VM directly into a hypervisor network, through the use of a bridge.
Start by creating a bridge on the hypervisor system:
> sudo ip link add br0 type bridge
Clear the IP address on the network interface that you'll be bridging (e.g. eth0).
Note: This will disable network traffic on eth0!
> sudo ip addr flush dev eth0Add the interface to the bridge:
> sudo ip link set eth0 master br0
Next up, create a TAP interface:
> sudo ip tuntap add dev tap0 mode tap user $(whoami)The user parameter ensures that the current user will be able to connect to the TAP interface.
Add the TAP interface to the bridge:
> sudo ip link set tap0 master br0
Make sure everything is up:
> sudo ip link set dev br0 up
> sudo ip link set dev tap0 up
The TAP interface is now ready for use. Assuming that a DHCP server is available on the bridged network, the VM can now obtain an IP address during boot via:
> qemu-kvm -kernel arch/x86/boot/bzImage \
-initrd initramfs \
-device e1000,netdev=network0,mac=52:55:00:d1:55:01 \
-netdev tap,id=network0,ifname=tap0,script=no,downscript=no \
-append "ip=dhcp rd.shell=1 console=ttyS0" -nographic
The MAC address is explicitly specified, so care should be taken to ensure its uniqueness.
The DHCP server response details are printed alongside network interface configuration. E.g.
[ 3.792570] e1000: eth0 NIC Link is Up 1000 Mbps Full Duplex, Flow Control: RX
[ 3.796085] IPv6: ADDRCONF(NETDEV_CHANGE): eth0: link becomes ready
[ 3.812083] Sending DHCP requests ., OK
[ 4.824174] IP-Config: Got DHCP answer from 10.155.0.42, my address is 10.155.0.1
[ 4.825119] IP-Config: Complete:
[ 4.825476] device=eth0, hwaddr=52:55:00:d1:55:01, ipaddr=10.155.0.1, mask=255.255.0.0, gw=10.155.0.254
[ 4.826546] host=rocksolid-sles, domain=suse.de, nis-domain=suse.de
...
Didn't get an IP address? There are a few things to check:
- Confirm that the kernel is built with boot-time DHCP client (CONFIG_IP_PNP_DHCP=y) and E1000 network driver (CONFIG_E1000=y) support.
- Check the -device and -netdev arguments specify a valid e1000 TAP interface.
- Ensure that ip=dhcp is provided as a kernel boot parameter, and that the DHCP server is up and running.
Update 20161223:
- Use 'ip' instead of 'brctl' to manipulate the bridge device - thanks Yagamy Light!
- Use 'ip tuntap' instead of 'tunctl' to create the TAP interface - thanks Johannes!
- For performance reasons, I strongly recommend using virtio network adapters instead of e1000.
September 19, 2020
Jelmer
Debian Janitor: Expanding Into Improving Multi-Arch
The Debian Janitor is an automated system that commits fixes for (minor) issues in Debian packages that can be fixed by software. It gradually started proposing merges in early December. The first set of changes sent out ran lintian-brush on sid packages maintained in Git. This post is part of a series about the progress of the Janitor.
As of dpkg 1.16.2 and apt 0.8.13, Debian has full support for multi-arch. To quote from the multi-arch implementation page:
Multiarch lets you install library packages from multiple architectures on the same machine. This is useful in various ways, but the most common is installing both 64 and 32- bit software on the same machine and having dependencies correctly resolved automatically. In general you can have libraries of more than one architecture installed together and applications from one architecture or another installed as alternatives.
The Multi-Arch specification describes a new Multi-Arch header which can be used to indicate how to resolve cross-architecture dependencies.
The existing Debian Multi-Arch hinter is a version of dedup.debian.net that compares binary packages between architectures and suggests fixes to resolve multi-arch problems. It provides hints as to what Multi- Arch fields can be set, allowing the packages to be safely installed in a Multi-Arch world. The full list of almost 10,000 hints generated by the hinter is available at https://dedup.debian.net/static/multiarch-hints.yaml.
Recent versions of lintian-brush now include a command called apply-multiarch-hints that downloads and locally caches the hints and can apply them to a package maintained in Git. For example, to apply multi-arch hints to autosize.js:
$ debcheckout autosize.js
declared git repository at https://salsa.debian.org/js-team/autosize.js.git
git clone https://salsa.debian.org/js-team/autosize.js.git autosize.js ...
Cloning into 'autosize.js'...
[...]
$ cd autosize.js
$ apply-multiarch-hints
Downloading new version of multi-arch hints.
libjs-autosize: Add Multi-Arch: foreign.
node-autosize: Add Multi-Arch: foreign.
$ git log -p
commit 3f8d1db5af4a87e6ebb08f46ddf79f6adf4e95ae (HEAD -> master)
Author: Jelmer Vernooij <jelmer@debian.org>
Date: Fri Sep 18 23:37:14 2020 +0000
Apply multi-arch hints.
+ libjs-autosize, node-autosize: Add Multi-Arch: foreign.
Changes-By: apply-multiarch-hints
diff --git a/debian/changelog b/debian/changelog
index e7fa120..09af4a7 100644
--- a/debian/changelog
+++ b/debian/changelog
@@ -1,3 +1,10 @@
+autosize.js (4.0.2~dfsg1-5) UNRELEASED; urgency=medium
+
+ * Apply multi-arch hints.
+ + libjs-autosize, node-autosize: Add Multi-Arch: foreign.
+
+ -- Jelmer Vernooij <jelmer@debian.org> Fri, 18 Sep 2020 23:37:14 -0000
+
autosize.js (4.0.2~dfsg1-4) unstable; urgency=medium
* Team upload
diff --git a/debian/control b/debian/control
index 01ca968..fbba1ae 100644
--- a/debian/control
+++ b/debian/control
@@ -20,6 +20,7 @@ Architecture: all
Depends: ${misc:Depends}
Recommends: javascript-common
Breaks: ruby-rails-assets-autosize (<< 4.0)
+Multi-Arch: foreign
Description: script to automatically adjust textarea height to fit text - NodeJS
Autosize is a small, stand-alone script to automatically adjust textarea
height to fit text. The autosize function accepts a single textarea element,
@@ -32,6 +33,7 @@ Package: node-autosize
Architecture: all
Depends: ${misc:Depends}
, nodejs
+Multi-Arch: foreign
Description: script to automatically adjust textarea height to fit text - Javascript
Autosize is a small, stand-alone script to automatically adjust textarea
height to fit text. The autosize function accepts a single textarea element,
The Debian Janitor also has a new multiarch-fixes suite that runs apply-multiarch-hints across packages in the archive and proposes merge requests. For example, you can see the merge request against autosize.js here.
For more information about the Janitor’s lintian-fixes efforts, see the landing page.
September 12, 2020
Jelmer
Debian Janitor: All Packages Processed with Lintian-Brush
The Debian Janitor is an automated system that commits fixes for (minor) issues in Debian packages that can be fixed by software. It gradually started proposing merges in early December. The first set of changes sent out ran lintian-brush on sid packages maintained in Git. This post is part of a series about the progress of the Janitor.
On 12 July 2019, the Janitor started fixing lintian issues in packages in the Debian archive. Now, a year and a half later, it has processed every one of the almost 28,000 packages at least once.
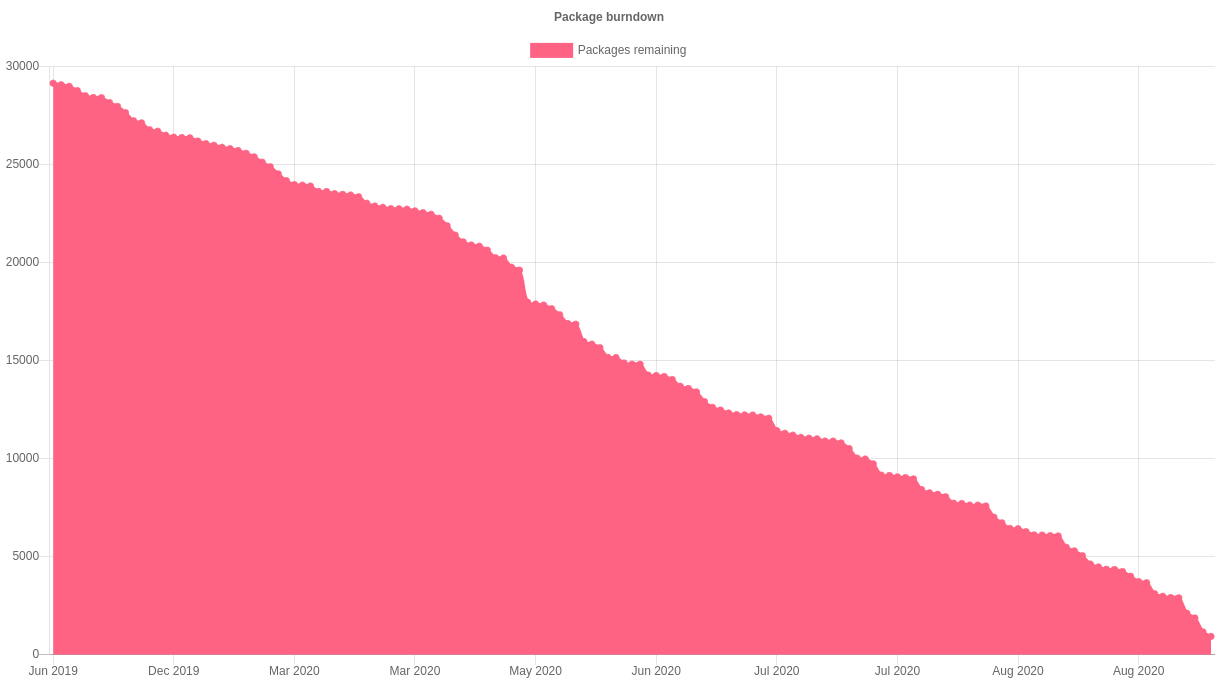
As discussed two weeks ago, this has resulted in roughly 65,000 total changes. These 65,000 changes were made to a total of almost 17,000 packages. Of the remaining packages, for about 4,500 lintian-brush could not make any improvements. The rest (about 6,500) failed to be processed for one of many reasons – they are e.g. not yet migrated off alioth, use uncommon formatting that can’t be preserved or failed to build for one reason or another.
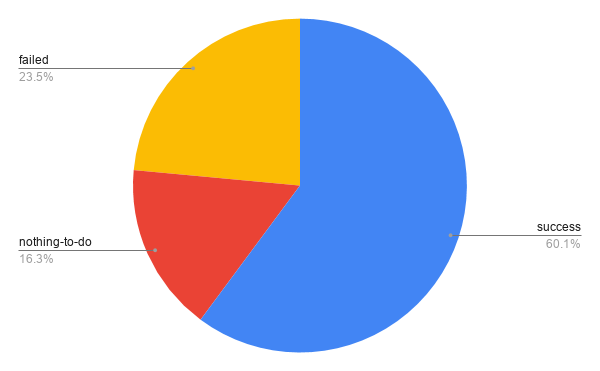
Now that the entire archive has been processed, packages are prioritized based on the likelihood of a change being made to them successfully.
Over the course of its existence, the Janitor has slowly gained support for a wider variety of packaging methods. For example, it can now edit the templates for some of the generated control files. Many of the packages that the janitor was unable to propose changes for the first time around are expected to be correctly handled when they are reprocessed.
If you’re a Debian developer, you can find the list of improvements made by the janitor in your packages by going to https://janitor.debian.net/m/.
For more information about the Janitor’s lintian-fixes efforts, see the landing page.
August 29, 2020
Jelmer
Debian Janitor: The Slow Trickle from Git Repositories to the Debian Archive
The Debian Janitor is an automated system that commits fixes for (minor) issues in Debian packages that can be fixed by software. It gradually started proposing merges in early December. The first set of changes sent out ran lintian-brush on sid packages maintained in Git. This post is part of a series about the progress of the Janitor.
Last week’s blog post documented how there are now over 30,000 lintian issues that have been fixed in git packaging repositories by the Janitor.
It’s important to note that any fixes from the Janitor that make it into a Git packaging repository will also need to be uploaded to the Debian archive. This currently requires that a Debian packager clones the repository and builds and uploads the package.
Until a change makes it into the archive, users of Debian will unfortunately not see the benefits of improvements made by the Janitor.
82% of the 30,000 changes from the Janitor that have made it into a Git repository have not yet been uploaded, although changes do slowly trickle in as maintainers make other changes to packages and upload them along with the lintian fixes from the Janitor. This is not just true for changes from the Janitor, but for all sorts of other smaller improvements as well.
However, the process of cloning and building git repositories and uploading the resulting packages to the Debian archive is fairly time-consuming – and it’s probably not worth the time of developers to follow up every change from the Janitor with a labour-intensive upload to the archive.
It would be great if it was easier to trigger uploads from git commits. Projects like tag2upload will hopefully help, and make it more likely that changes end up in the Debian archive.
The majority packages do get at least one new source version upload per release, so most changes will eventually make it into the archive.
For more information about the Janitor’s lintian-fixes efforts, see the landing page.
August 22, 2020
Jelmer
Debian Janitor: > 60,000 Lintian Issues Automatically Fixed
The Debian Janitor is an automated system that commits fixes for (minor) issues in Debian packages that can be fixed by software. It gradually started proposing merges in early December. The first set of changes sent out ran lintian-brush on sid packages maintained in Git. This post is part of a series about the progress of the Janitor.
Scheduling Lintian Fixes
To determine which packages to process, the Janitor looks at the import of lintian output across the archive that is available in UDD [1]. It will prioritize those packages with the most and more severe issues that it has fixers for.
Once a package is selected, it will clone the packaging repository and run lintian-brush on it. Lintian-brush provides a framework for applying a set of “fixers” to a package. It will run each of a set of “fixers” in a pristine version of the repository, and handles most of the heavy lifting.
The Inner Workings of a Fixer
Each fixer is just an executable which gets run in a clean checkout of the package, and can make changes there. Most of the fixers are written in Python or shell, but they can be in any language.
The contract for fixers is pretty simple:
- If the fixer exits with non-zero, the changes are reverted and fixer is considered to have failed
- If it exits with zero and made changes, then it should write a summary of its changes to standard out
If a fixer is uncertain about the changes it has made, it should report so on standard output using a pseudo-header. By default, lintian-brush will discard any changes with uncertainty but if you are running it locally you can still apply them by specifying --uncertain.
The summary message on standard out will be used for the commit message and (possibly) the changelog message, if the package doesn’t use gbp dch.
Example Fixer
Let’s look at an example. The package priority “extra” is deprecated since Debian Policy 4.0.1 (released August 2 017) – see Policy 2.5 “Priorities”. Instead, most packages should use the “optional” priority.
Lintian will warn when a package uses the deprecated “extra” value for the “Priority” - the associated tag is priority-extra-is-replaced-by-priority-optional. Lintian-brush has a fixer script that can automatically replace “extra” with “optional”.
On systems that have lintian-brush installed, the source for the fixer lives in /usr/share/lintian-brush/fixers/priority-extra-is-replaced-by-priority-optional.py, but here is a copy of it for reference:
1 2 3 4 5 6 7 8 9 10 11 12 13 | #!/usr/bin/python3
from debmutate.control import ControlEditor
from lintian_brush.fixer import report_result, fixed_lintian_tag
with ControlEditor() as updater:
for para in updater.paragraphs:
if para.get("Priority") == "extra":
para["Priority"] = "optional"
fixed_lintian_tag(
para, 'priority-extra-is-replaced-by-priority-optional')
report_result("Change priority extra to priority optional.")
|
This fixer is written in Python and uses the debmutate library to easily modify control files while preserving formatting — or back out if it is not possible to preserve formatting.
All the current fixers come with tests, e.g. for this particular fixer the tests can be found here: https://salsa.debian.org/jelmer/lintian-brush/-/tree/master/tests/priority-extra-is-replaced-by-priority-optional.
For more details on writing new fixers, see the README for lintian-brush.
For more details on debugging them, see the manual page.
Successes by fixer
Here is a list of the fixers currently available, with the number of successful merges/pushes per fixer:
Footnotes
| [1] | temporarily unavailable due to Debian bug #960156 – but the Janitor is relying on historical data |
For more information about the Janitor’s lintian-fixes efforts, see the landing page.
August 15, 2020
Jelmer
Debian Janitor: 8,200 landed changes landed so far
The Debian Janitor is an automated system that commits fixes for (minor) issues in Debian packages that can be fixed by software. It gradually started proposing merges in early December. The first set of changes sent out ran lintian-brush on sid packages maintained in Git. This post is part of a series about the progress of the Janitor.
The bot has been submitting merge requests for about seven months now. The rollout has happened gradually across the Debian archive, and the bot is now enabled for all packages maintained on Salsa, GitLab, GitHub and Launchpad.
There are currently over 1,000 open merge requests, and close to 3,400 merge requests have been merged so far. Direct pushes are enabled for a number of large Debian teams, with about 5,000 direct pushes to date. That covers about 11,000 lintian tags of varying severities (about 75 different varieties) fixed across Debian.


For more information about the Janitor’s lintian-fixes efforts, see the landing page.
August 08, 2020
Jelmer
Improvements to Merge Proposals by the Janitor
The Debian Janitor is an automated system that commits fixes for (minor) issues in Debian packages that can be fixed by software. It gradually started proposing merges in early December. The first set of changes sent out ran lintian-brush on sid packages maintained in Git. This post is part of a series about the progress of the Janitor.
Since the original post, merge proposals created by the janitor now include the debdiff between a build with and without the changes (showing the impact to the binary packages), in addition to the merge proposal diff (which shows the impact to the source package).
New merge proposals also include a link to the diffoscope diff between a vanilla build and the build with changes. Unfortunately these can be a bit noisy for packages that are not reproducible yet, due to the difference in build environment between the two builds.
This is part of the effort to keep the changes from the janitor high-quality.
The rollout surfaced some bugs in lintian-brush; these have been either fixed or mitigated (e.g. by disabling specified fixers).
For more information about the Janitor’s lintian-fixes efforts, see the landing page.
June 28, 2020
Andreas
OpenStreetMap for Garmin Fenix
I’ve recently bought a Garmin Fenix Multisport Smartwatch. The watch offers support for navigation and maps. By default it came with some topo maps for Europe. However I wanted to use more detailed maps from OpenStreetMap.
 Freizeitkarte for Garmin Fenix loaded into QMapShack
Freizeitkarte for Garmin Fenix loaded into QMapShackAfter some search I’ve discovered the wonderful Freizeitkarte project, which is a project to offer maps for Garmin devices. The default maps work OKish on the device. However as the smart watch doesn’t have a high end processor zooming and fast scrolling on the map is very slow. Also the display of the Fenix isn’t very saturated, so you need to work with different contrasts to display the map nicely.
So I’ve downloaded the Freizeitkarte Map Development Environment (MDE) and tried to find out how the map is generated and how you could improve it. It is really simple to use and well documented!
First I removed power lines from the map, you really don’t need them on a fitness tracker and they often confused me because the display was similar to roads and it looks like the is a junction of a road but there wasn’t a road.
Then I reduced the Points of Interest (POI) to remove what we really don’t need. Things like car, beauty or fashion shops, power and communication towers, bowling and horse stuff and many more.
The next step as to improve the look of the map. The MDE comes already with different files which define how a map looks, those are called TYP files. It has an outdoorc.TYP file which has a more contrasty look for a map but not enough for the Fenix. So I created a new TYP file especially for the Fenix and improved some icons I find important like restaurants, supermarkets, pharmacies and hospitals, parking lots and (bus) stops.


Also there had been problems with the map on fenix. The draw order really matters and I needed to draw forests earlier as they didn’t show up on smartwatch, but worked fine when loaded in QMapShack.
My current version of the Fenix style for Freizeitkarte can be found in a Merge Request (MR) for FZK MDE.
If you want to play with an already rendered map, I’ve uploaded a map of Bavaria and the Alps here:
fzk_fenix_bavaria_de.img.xz (262 MB)
fzk_fenix_alps_de.img.xz (1.4 GB)
Download the file, unzip it and copy the fenix_fzk_bayern_de.img to the GARMIN folder on the device using MTP. Make sure to use None as the Map theme to get the one from the map!
In case you want a map for your region you can build it yourself using the MDE.
Here are my build steps:
# Build Freizeitkarte for Fenix
1. Bootstrap (needed only once)
./mt.pl bootstrap urls http://osm.thkukuk.de/data/bounds-latest.zip http://osm.thkukuk.de/data/sea-latest.zip
./mt.pl create
2. Fetch OSM and Elevation and join them
./mt.pl --downloadbar fetch_osm Freizeitkarte_BAYERN
./mt.pl --downloadbar fetch_ele Freizeitkarte_BAYERN
./mt.pl --ram=22528 --cores=11 join Freizeitkarte_BAYERN
3. Split and build the map
./mt.pl --ram=22528 --cores=11 --language=de split Freizeitkarte_BAYERN
./mt.pl --ram=22528 --cores=11 --typfile=fenix.TYP --style=fzk-fenix --language=de build Freizeitkarte_BAYERN
./mt.pl --ram=22528 --cores=11 --typfile=fenix.TYP --style=fzk-fenix --language=de gmapsupp Freizeitkarte_BAYERN
Note: For using 1 CPU core you need 2GB of RAM. I have 12 cores (24 threads) and 32GB of RAM in my machine. The above values I use are a good compromise between speed and a still usable system :-)Feedback is welcome as well as code/style contributions.
May 27, 2020
Rusty
57 Varieties of Pyrite: Exchanges Are Now The Enemy of Bitcoin
TL;DR: exchanges are casinos and don’t want to onboard anyone into bitcoin. Avoid.
There’s a classic scam in the “crypto” space: advertize Bitcoin to get people in, then sell suckers something else entirely. Over the last few years, this bait-and-switch has become the core competency of “bitcoin” exchanges.
I recently visited the homepage of Australian exchange btcmarkets.net: what a mess. There was a list of dozens of identical-looking “cryptos”, with bitcoin second after something called “XRP”; seems like it was sorted by volume?
Incentives have driven exchanges to become casinos, and they’re doing exactly what you’d expect unregulated casinos to do. This is no place you ever want to send anyone.
Incentives For Exchanges
Exchanges make money on trading, not on buying and holding. Despite the fact that bitcoin is the only real attempt to create an open source money, scams with no future are given false equivalence, because more assets means more trading. Worse than that, they are paid directly to list new scams (the crappier, the more money they can charge!) and have recently taken the logical step of introducing and promoting their own crapcoins directly.
It’s like a gold dealer who also sells 57 varieties of pyrite, which give more margin than selling actual gold.
For a long time, I thought exchanges were merely incompetent. Most can’t even give out fresh addresses for deposits, batch their outgoing transactions, pay competent fee rates, perform RBF or use segwit.
But I misunderstood: they don’t want to sell bitcoin. They use bitcoin to get you in the door, but they want you to gamble. This matters: you’ll find subtle and not-so-subtle blockers to simply buying bitcoin on an exchange. If you send a friend off to buy their first bitcoin, they’re likely to come back with something else. That’s no accident.
Looking Deeper, It Gets Worse.
Regrettably, looking harder at specific exchanges makes the picture even bleaker.
Consider Binance: this mainland China backed exchange pretending to be a Hong Kong exchange appeared out of nowhere with fake volume and demonstrated the gullibility of the entire industry by being treated as if it were a respected member. They lost at least 40,000 bitcoin in a known hack, and they also lost all the personal information people sent them to KYC. They aggressively market their own coin. But basically, they’re just MtGox without Mark Karpales’ PHP skills or moral scruples and much better marketing.
Coinbase is more interesting: an MBA-run “bitcoin” company which really dislikes bitcoin. They got where they are by spending big on regulations compliance in the US so they could operate in (almost?) every US state. (They don’t do much to dispel the wide belief that this regulation protects their users, when in practice it seems only USD deposits have any guarantee). Their natural interest is in increasing regulation to maintain that moat, and their biggest problem is Bitcoin.
They have much more affinity for the centralized coins (Ethereum) where they can have influence and control. The anarchic nature of a genuine open source community (not to mention the developers’ oft-stated aim to improve privacy over time) is not culturally compatible with a top-down company run by the Big Dog. It’s a running joke that their CEO can’t say the word “Bitcoin”, but their recent “what will happen to cryptocurrencies in the 2020s” article is breathtaking in its boldness: innovation is mainly happening on altcoins, and they’re going to overtake bitcoin any day now. Those scaling problems which the Bitcoin developers say they don’t know how to solve? This non-technical CEO knows better.
So, don’t send anyone to an exchange, especially not a “market leading” one. Find some service that actually wants to sell them bitcoin, like CashApp or Swan Bitcoin.
December 03, 2019
Jelmer
The Debian Janitor
There are a lot of small changes that can be made to the Debian archive to increase the overall quality. Many of these changes are small and have just minor benefits if they are applied to just a single package. Lintian encourages maintainers to fix these problems by pointing out the common ones.
Most of these issues are often trivially fixable; they are in general an inefficient use of human time, and it takes a lot of effort to keep up with. This is something that can clearly be automated.
Several tools (e.g. onovy’s mass tool, and the lintian-brush tool that I’ve been working on) go a step further and (for a subset of the issues reported by lintian) fix the problems for you, where they can. Lintian-brush can currently fix most instances of close to 100 lintian tags.
Thanks to the Vcs-* fields set by many packages and the APIs provided by hosting platforms like Salsa, it is now possible to proactively attempt to fix these issues.
The Debian Janitor is a tool that will run lintian-brush across the entire archive, and propose fixes to lintian issues via pull request.
Objectives
The aim of Debian Janitor is to take some drudge work away from Debian maintainers where possible, so they can spend their time on more important packaging work. Its purpose is to make automated changes quick and easy to apply, with minimal overhead for package maintainers. It is essentially a bit of infrastructure to run lintian-brush across all of the archive.
The actions of the bot are restricted to a limited set of problems for which obviously correct actions can be taken. It is not meant to automate all packaging, or even to cover automating all instances of the issues it knows about.
The bot is designed to be conservative and delight with consistently correct fixes instead of proposing possibly incorrect fixes and hoping for the best. Considerable effort has been made to avoid the janitor creating pull requests with incorrect changes, as these take valuable time away from maintainers, the package doesn’t actually improve (since the merge request is rejected) and it makes it likelier that future pull requests from the Debian Janitor bot are ignored or rejected.
In short: The janitor is meant to propose correct changes if it can, and back off otherwise.
Design
The Janitor finds package sources in version control systems from the Vcs*- control field in Debian source packages. If the packaging branch is hosted on a hosting platform that the Janitor has a presence on, it will attempt to run lintian-brush on the packaging branch and (if there are any changes made) build the package and propose a merge. It is based on silver-platter and currently has support for:
The Janitor is driven from the lintian and vcswatch tables in UDD. It queries for packages that are affected by any of the lintian tags that lintian-brush has a fixer script for. This way it can limit the number of repositories it has to process.
Ensuring quality
There are a couple of things I am doing to make sure that the Debian Janitor delights rather than annoys.
High quality changes
Lintian-brush has end-to-end tests for its fixers.
In order to make sure that merge requests are useful and high-value, the bot will only propose changes from lintian-brush that:
- successfully build in a chroot and pass autopkgtest and piuparts;
- are not completely trivial - e.g. only stripping whitespace
Changes for a package will also be reviewed by a human before they make it into a pull request.
One open pull request per package
If the bot created a pull request previously, it will attempt to update the current request by adding new commits (and updating the pull request description). It will remove and fix the branch when the pull request conflicts because of new upstream changes.
In other words, it will only create a single pull request per package and will attempt to keep that pull request up to date.
Gradual rollout
I’m slowly adding interested maintainers to receiving pull requests, before opening it up to the entire archive. This should help catch any widespread issues early.
Providing control
The bot will be upfront about its pull requests and try to avoid overwhelming maintainers with pull requests by:
- Clearly identifying any merge requests it creates as being made by a bot. This should allow maintainers to prioritize contributions from humans.
- Limiting the number of open proposals per maintainer. It starts by opening a single merge request and won’t open additional merge requests until the first proposal has a response
- Providing a way to opt out of future merge requests; just a reply on the merge request is sufficient.
Any comments on merge requests will also still be reviewed by a human.
Current state
Debian janitor is running, generating changes and already creating merge requests (albeit under close review). Some examples of merge requests it has created:
Using the janitor
The janitor can process any package that’s maintained in Git and has its Vcs-Git header set correctly (you can use vcswatch to check this).
If you’re interested in receiving pull requests early, leave a comment below. Eventually, the janitor should get to all packages, though it may take a while with the current number of source packages in the archive.
By default, salsa does not send notifications when a new merge request for one of the repositories you’re a maintainer for is created. Make sure you have notifications enabled in your Salsa profile, by ticking “New Merge Requests” for the packages you care about.
You can also see the number of open merge requests for a package repository on QA - it’s the ! followed by a number in the pull request column.
It is also possible to download the diff for a particular package (if it’s been generated) ahead of the janitor publishing it:
$ curl https://janitor.debian.net/api/lintian-fixes/pkg/PACKAGE/diff
E.g. for i3-wm, look at https://janitor.debian.net/api/lintian-fixes/pkg/i3-wm/diff.
Future Plans
The current set of supported hosting platforms covers the bulk of packages in Debian that is maintained in a VCS. The only other 100+ package platform that’s unsupported is dgit. If you have suggestions on how best to submit git changes to dgit repositories (BTS bugs with patches? or would that be too much overhead?), let me know.
The next platform that is currently missing is bitbucket, but there are only about 15 packages in unstable hosted there.
At the moment, lintian-brush can fix close to 100 lintian tags. It would be great to add fixers for more common issues.
The janitor should probably be more tightly integrated with other pieces of Debian infrastructure, e.g. Jenkins for running jobs or linked to from the tracker or lintian.debian.org.
More information
If you have any concerns about these roll-out plans, have other ideas or questions, please let me know in the comments.
November 26, 2019
Andreas
AVIF (12/10/8-bit) image support for darktable
As I’m an amateur photographer, I’m using Open Source tools for developing my images. The software I use is called darktable. I think it is the best tool out there for editing RAW images.
From time to time I contributed small code changes to darktable, mostly bug fixes. Now I nearly finished my first feature for darktable, support for the AVIF image format.
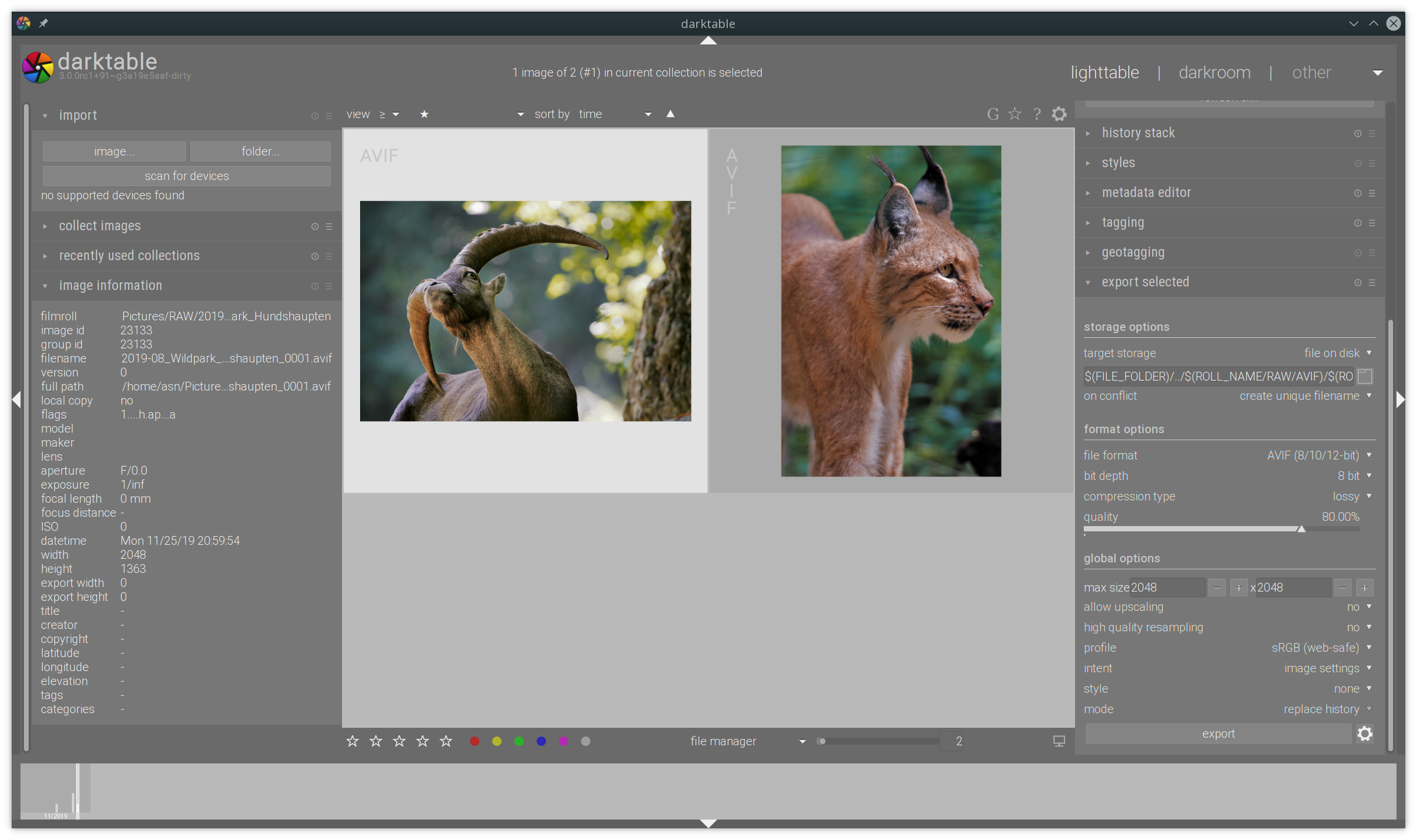 From RAW exported and reimported AVIF images in darktable.
From RAW exported and reimported AVIF images in darktable.
For implementing AVIF support I used libavif. Joe Drago the author of libavif was very helpful explaining all the details and helping me in debugging issues. Thank you Joe!
The code need to be polished a bit more and I need to decide what to expose in the export UI or better simplify for the user.
However there are some outstanding things that this will be a great experience for everyone:
Multi threaded encoding of AVIF images using rav1e in libavifStill image support in rav1e- Lossless support in rav1e
- AVIF image support in exiv2
- AVIF image support in Firefox (FYI: Firefox already uses dav1d playing for AV1 videos)
Last updated: June 13, 2021 07:00 PM